PurposeThis document specifies the requirements for a Source Code Search Engine.
ScopeThe goal of using search engines is to obtain quality search results efficiently. The Source Code Search Engine can be used to find out example programs where a particular construct has been used. A user can have a look at these programs so that the manner of use and the context can be understood.
Overview
ProblemThe source code search engine is supposed to do the following The user specifies certain key words. The search engine searches for fragments of source code containing it.Fast operation of the search engine
High quality search results
Keeping the database up to date - fast crawling technology
Efficient use of space for storing the database
Proposed Solution
Requirements include:Use Case ModelServer:Steps Involved:The server is always up.Database:Database is to be updated at periodic intervals.User Interface:The user will be able to provide certain keywords.Search:The database will be traversed and the required pages determined. Junk results are to be avoided.Presentation of results:The results will be presented to the user in the order of importance. It will be given in batches of n (which the user may specify if necessary) each.DNS caches:The crawler will have to maintain a cache of recent DNS lookups so that the process of crawling will be high.
- Acceptance of query
- Query evaluation
- Retreival of results from the database
- Presentation of results to the user.
Databases:Queue:Relevant webpages are stored for further processing.Database:This will store the page entries and the hitlist. Each page entry will contain fields includingResult Cache:Page ID: This is used to access the entry.The hitlist associates a key word to the page entries corresponding to pages containing it Associated with each pair of page entry and key word, is an anchor text which is a description of the occurrence of the keyword in the page.
Page Rank: This will give the importance associated with a page.
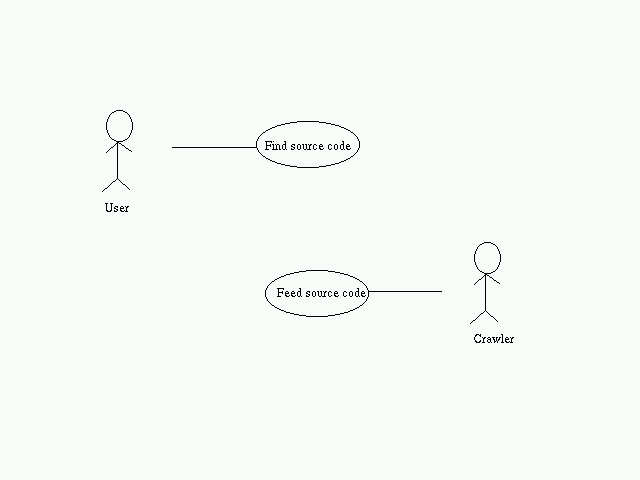
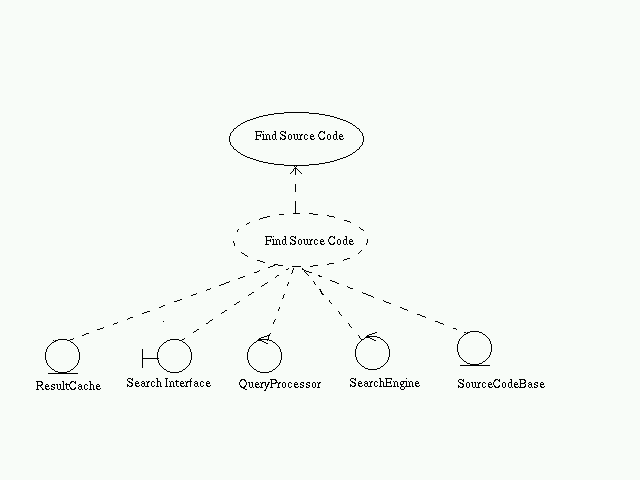
Page URL: This will contain the link to the page.Recent search results can be stored here for fast access.Find Source Code:
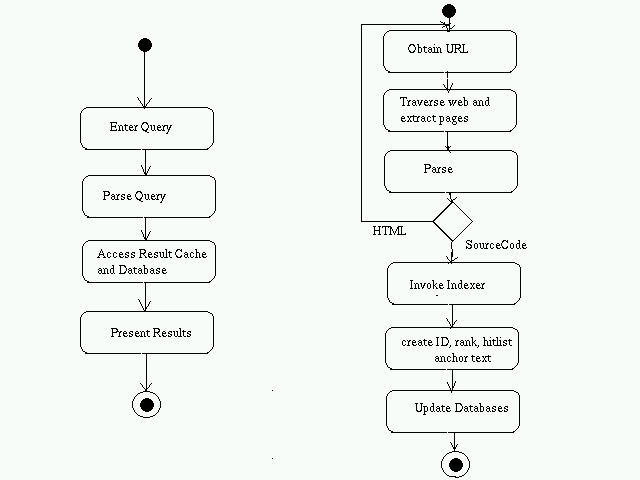
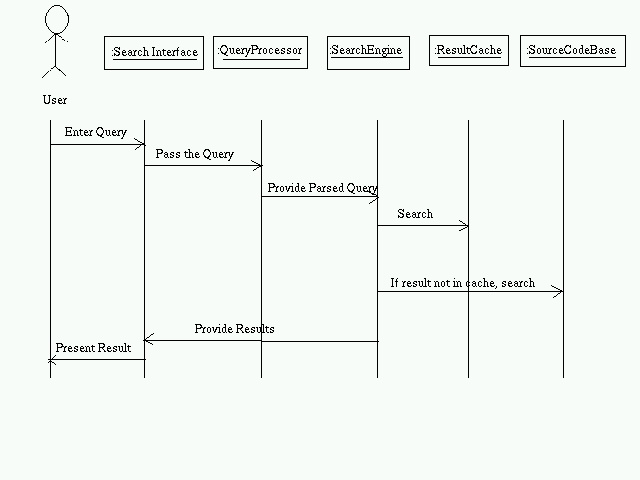
- User enters the query
- Query is passed onto the query processor
- QueryProcessor parses it.
- SearchEngine finds the entries corresponding to the parsed query from the ResultCache. In case it is not present there, it is taken from the SourceCodeBase
- The results are presented to the user.
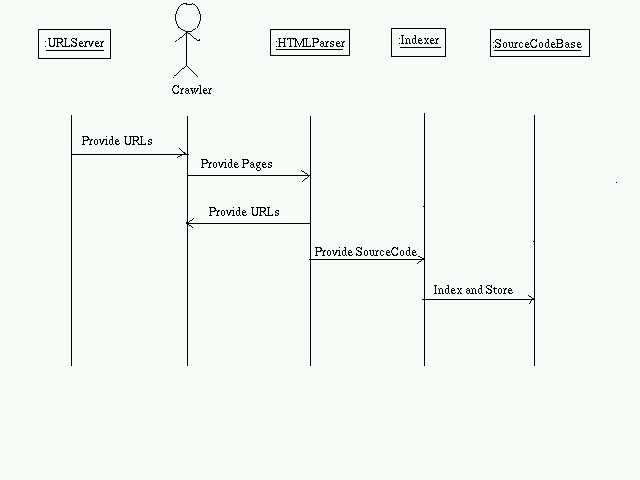
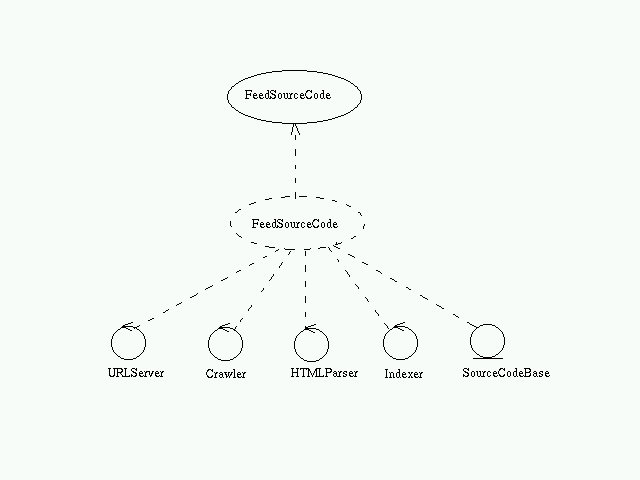
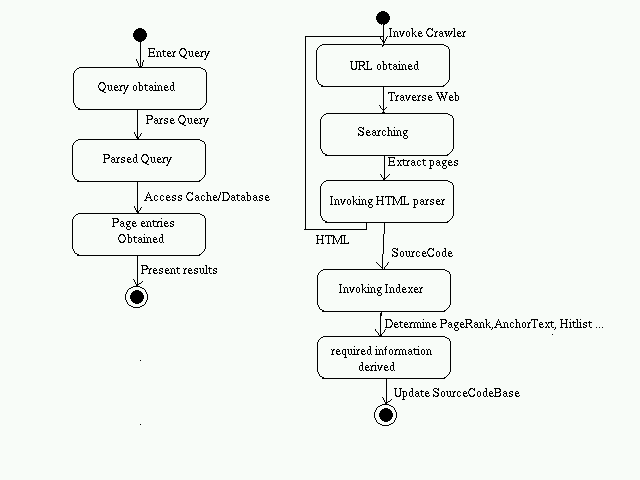
Feed Source Code:
- URLServer provides an initial set of URLs to the Crawler
- The Crawler traverses the web and extracts pages.
- HTMLParser extracts the URLs and passes it to the crawler
- If the page is source code, pass it to the indexer.
- The indexer creates pagerank, hitlist, ... and stores it in SourceCodeBase.
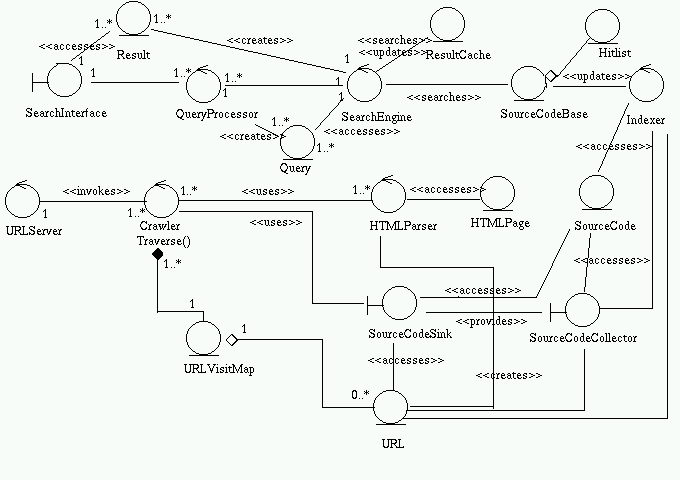
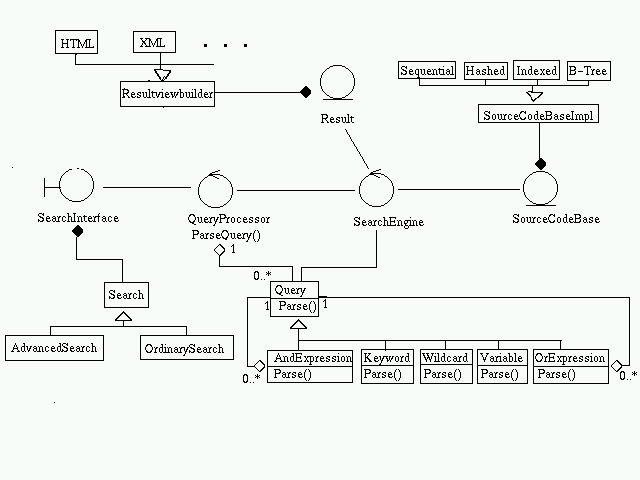
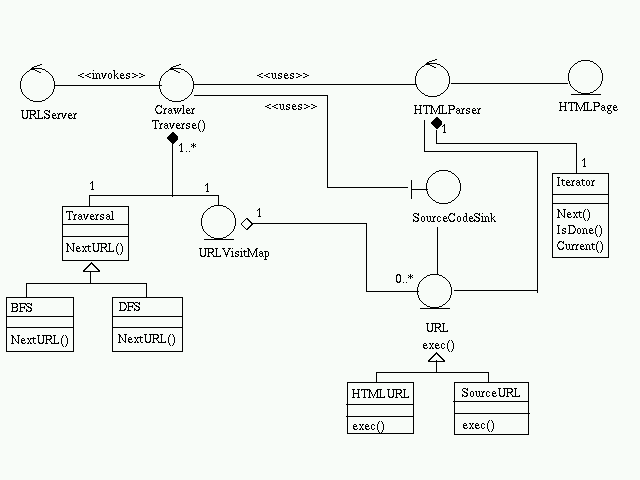
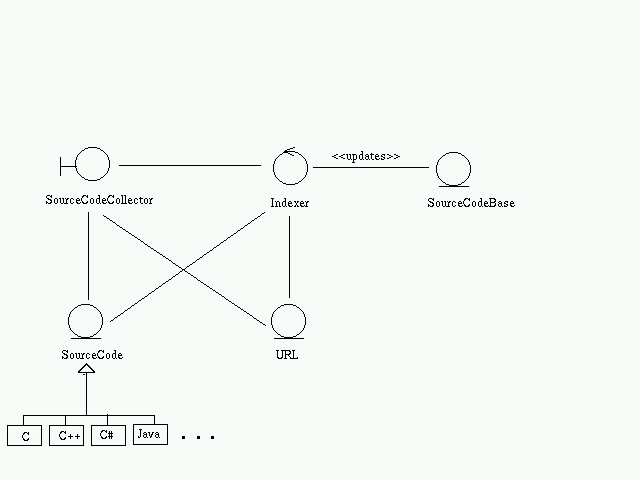
Class DiagramArchitecture SpecificationBoundary Classes
SearchInterface:Entity ClassesThis provides the general interface through which the user interacts with the system.SourceCodeSink:This is the interface in the crawler subsystem that interacts with the indexer subsystem.SourceCodeCollector:This is the interface in the indexer subsystem that interacts with the crawler subsystem.SourceCodeBaseControl ClassesThe hitlist and page entry obtained after processing by the sorter.Result Cache
The various fields of each entry will be
- Keyword
- Hitlist
The result cache can be used to store the recent search results.QueryThe query the user enters is parsed and stored in this class. The SearchEngine uses the class.ResultThe search results are passed to the SearchInterface using this class.URLVisitMapThis is used to determine if a page has already been visited or not.HTMLPage
- URL
- visited: boolean
Pages extracted by the crawler are stored in this class.URLURL corresponding to pages are stored in this.SourceCodeThe SourceCode extracted by the crawler are passed on to the indexer using this class.HitlistThis entity class stores the page entries, and anchor text corresponding to each keyword.
The various fields in each entry are
- PageID
- PageURL
- PageRank
- AnchorText
QueryProcessorActive ClassThis parses the query provided by the search interface.SearchEngineUses Query to search the ResultCache. In case of failure, it accesses the SourceCodeBase, and also updates the ResultCache.IndexerIt takes the source code provided by the crawler subsystem, and creates the pageid, pagerank, anchortext,.... and stores it in the SourceCodeBase.URLServerThis provides an initial set of URLs to the crawler, and invokes it periodically.CrawlerThis traverses the web and collects pages. If the page is source code, it is passed on to the indexer subsystem. Else it is passed to the HTMLParser.HTMLParserIt extracts URLs from pages and passes it on to the Crawler.URL ServerCollaborationThis initiates the crawling.Find Source CodeUse Case Realization
Feed Source CodeFeed Source CodeState Chart DiagramsFind Source Code
Activity Diagrams
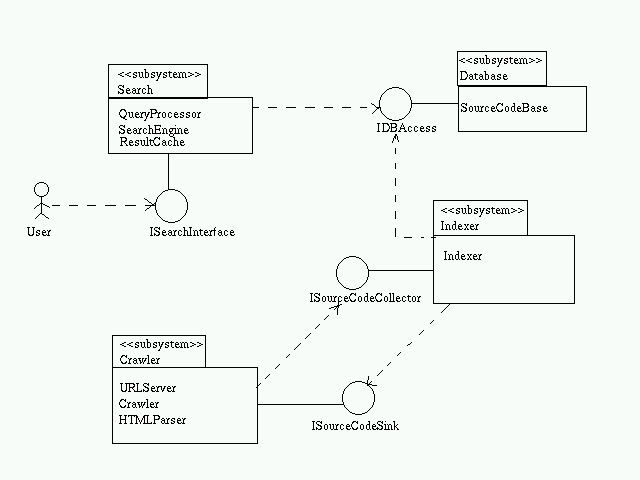
The overall system can be considered to be composed of four subsystems.
- Search Subsystem
- Indexer Subsystem
- Crawler Subsystem
- Database Subsystem
These subsystems can be shown in detail.
- Search Subsystem
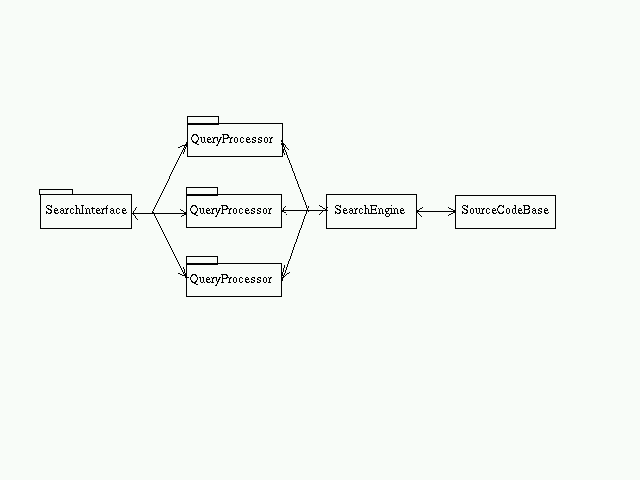
The search subsystem is responsible for finding the search results corresponding to the query raised by the user. A SearchInterface is provided which accepts the query from the user and passes it onto the QueryProcessor. More than one QueryProcessor may exist.
- Crawler Subsystem
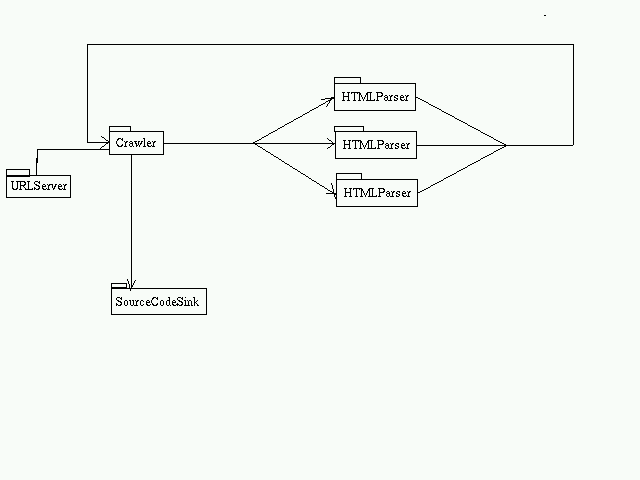
The URLServer provides the initial set of URLs to the crawler which traverses the web and extracts pages. These pages may consist of HTML or source code. If it is source code, it is passed directly to the SourceCodeSink. For HTML pages, the HTMLParser extracts the URLs and returns it to the crawler.
- Indexer Subsystem
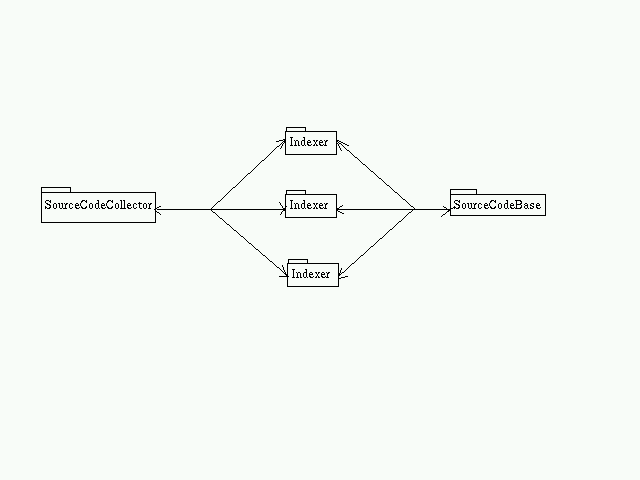 The SourceCodeCollector passes on the source code to an Indexer which calculates the PageID, PageRank, AnchorText, ... and saves it on the SourceCodeBase.Employing connectors helps in keeping the various components on different machines if necessary.
The SourceCodeCollector passes on the source code to an Indexer which calculates the PageID, PageRank, AnchorText, ... and saves it on the SourceCodeBase.Employing connectors helps in keeping the various components on different machines if necessary.Architectural Styles Used are
- Layering
The architecture can be viewed as a collection of layers. The different layers are
- SearchInterface: It accepts the query from the user and presents the results. It uses the query processor to parse the query
- Query Processor: It parses the query and provides the information to the search engine, which is the underlying layer
- SearchEngine: SearchEngine takes the information provided by the query processor and searches for the results.
- SourceCodeBase: Information about pages will be stored in this layer.
- Thin Client Web Architecture
Thin Client Web Architecture can be used in the Search Subsystem since the client need not do any sophisticated processing.
Good FeaturesThe client need not have any sophisticated capabilities. All processing is done by the server. The client only needs to enter the query. After all processing by the server, results are forwarded to the client.
Bad FeaturesAll processing will have to be done by the server.
- Pipe and Filter:
It is used in the indexer subsystem. The Indexer acts as a filter and processes the sourcecode available.
- Broker:
The use of connectors facilitates the use of broker architectural pattern. The broker architecture can be used to cover the issues related to distributed processing.
Design ModelThe class diagram corresponding to the different subsystems are shown below.
- Search Subsytem
Design Patterns Used:
Bridge
The database can be implemented in different ways - sequential, hashed, indexed, B trees, etc. In order to separate the abstraction from implementation, the Bridge pattern can be used. The operations on the database can be performed irrespective of the underlying structure.
InterpreterStrategy
The query processor parses the query. The query is an expression. The expression can be a keyword, a wildcard, a variable, or a combination of expressions using 'and 'or 'or'. The Interpreter pattern captures this idea.The Composite design pattern can be used instead of the Interpreter design by taking the query as the composition of leaves (keyword, wildcard, variable) and composite (and expression, or expression).
The search can be done in two modes. It can either be an ordinary search, or an advanced search where the user will be able to specify more details. Similarly, the presentation can also be done in different formats like HTML, XML, ... The strategy design pattern fits in here.
Decorator:A decorator design pattern may be used to provide various embellishments while designing the user interface.
- Crawler Subsystem
Design Patterns Used:
StrategyThe algorithm using which the traversal of the crawler is done can be modelled by the Strategy design pattern. Here the context is crawler, strategy is traversal and the concrete strategies are specific algorithms like bfs, dfs etc.
IteratorAn iterator can be used for iterating over HTML pages, provided by the crawler, in the HTMLParser.
- Indexer Subsystem