Abstract:
In current processors using paged virtual memory, the Memory Management Unit (MMU) has the unenviable task of translating application virtual addresses into physical addresses. The key to efficiently performing this task is caching recent virtual to physical address translations in the Translation Lookaside Buffer (TLB). TLB is becoming main component of critical path in processor performance. Already in deep pipelined processor 1-2 cycles are for spend on TLB access. So there is increasing pressure on TLB for speed . With large increase in main memory and program size, TLB miss are becoming significant factor of program execution. It is only recent that mechanisms for TLB prefecting are proposed.
In this paper, some of the proposed TLB prefecting mechanism are evaluated. This includes Recency based prefecting(RP), Distance prefecting(DP), Sequential prefecting (SP), Markov prefecting (MP), Arbitrary Stride Prefetching (ASP).
1. Problem definition
The importance of the Translation Lookaside Buffer(TLB) on system performance is well known. There have been numerous prior efforts addressing TLB design issues for cutting down access times and lowering miss rates. TLB miss handling has been shown to constitute as much as 40% of execution time and upto 90% of a kernel's computation . Studies with specific applications have also shown that the TLB miss rate can account for over 10% of their execution time even with an optimistic 30-50 cycle miss overhead. [1] has already shown TLB thrashing in commercial code.
Increasing the capacity of TLB increases it's search and access latency, hence impacting memory access time. This can degrade the performance heavily. In processors with physically tagged first level cache, TLB latency is major factor. These two forces have resulted in ways to increase TLB capacity without impacting its latency. Various solutions to this problem like limited associativity, increasing the page size, multilevel of TLB, compiler optimization to feet current working set into smaller region are proposed. None of these seem satisfactory.
There is already lot of study is done on reducing miss penalties on other (especially cache) memory hierarchy. But surprisingly enough, there is very less study done on reducing TLB miss penalty. It is just recent that, preloading TLB before there need to reduce miss penalties is explored. Some of these consider only prefecting to minimize cold starting misses. This may be small fraction in long running program. The first work to capacity related misses has been undertaken in [1]. In [2] some of the strategy that were proposed for cache are modified and evaluated for TLB.
In the next sections we see all these strategy for TLB prefecting. In last section we conclude with comparison.
2. Prefetching Mechanisms
In this section we briefly go over five proposed mechanisms. It should be noted that out of these only Recency based prefecting & distance prefecting are mechanisms that were proposed to handle TLB miss. Other are borrowed large body of literature on prefecting cache.
2.1 Sequential Prefecting(SP)
This mechanism try to exploit the spatial locality in access. Whenever a miss occurred for a TLB entry, along with missed TLB entry, TLB entry corresponding to next virtual page is prefetched. Several variations to SP has been proposed. Most effective out of this is a tagged sequential prefecting, where a prefetch is initiated on every demand fetch and on every first hit
On a TLB miss, if the translation also misses in the prefetch buffer, it is demand fetched and a prefetch is initiated for the next virtual page translation (stride = 1) from the page table. The CPU resumes as soon as the demand page translation arrives. In case of a prefetch buffer hit, CPU is given back the translation, the entry is moved to the TLB, and a prefetch is initiated for the next translation in the background. Only one entry is prefected in this scheme.
2.2 Arbitrary Stride Prefetching (ASP)
While SP tries with spatial locality, most of application access elements in regular strided pattern. Each row in ASP table (also called Reference Prediction Table(RPT)) contains address that was referred last time, corresponding stride, and PC tag. Each row is indexed by PC. Address field is updated each time PC comes to this instruction. Prefect is initiated only when there is no change in stride for more than last two references. It tries to avoid spurious changes in stride. It is representative of schemes that attempt to detect regularity of accesses. This scheme requires good amount of hardware and can prefetches only one page. Whenever a entry is referred, entry corresponding to last referred address is also checked. If it is not present then prefected is initiated in background.
2.3 Markov prefecting(MP)
This technique is able to detect repetition of history even though there is no regularity in strides. This contrast with previous techniques which can detect only regular stride pattern in access stream. This is quite natural in pointer extensive application. MP attempts to dynamically build a Markov state transition diagram with states denoting the referenced unit (pages in this context) and transition arcs denoting probability of needing the next page table entry when the current page is accessed. The probabilities are tracked from prior references to that unit, and a table is used to approximate this state diagram. Each row in table contains `s' entries for prediction page. Normally `s' is set to 2. Now Whenever a page is referred, corresponding `s' pages can be prefetched. In addition, we also go to the entry of the previous page that missed, and add the current miss address into one of its slots (whichever is free). If all the slots are occupied, then we evict one based on LRU policy. Each entry in prediction table is indexed by page. Whenever a miss occurs, in addition to missed entry, entries corresponding to prediction table are also prefected. This imply that entries in prefect table corresponds to virtual page number. Processor resume its operation as soon as required entry is available.
2.4 Recency based prefecting(RP)
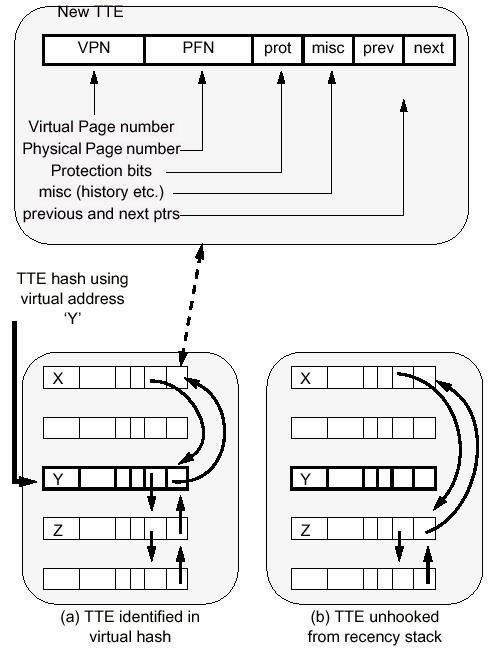
This is the first technique that is derived for TLB prefecting. This mechanism works on the principle that pages referenced at around the same time in the past will also be referenced at around the same time in the future. A deterministic iterative application generally loop through data structure in same order during computation. So this scheme assumes that given a TLB miss next miss will have same recency' as previous one. For this purpose a LRU stack of page table entries is maintained. LRU stack maintains a logical ordering of accesses, such that the most recent are at the top and the least recent are at the bottom. In particular, at every stage in the above process, the top K elements of the stack represent the K most recently referenced addresses.
Temporal ordering of LRU stack can be maintained using doubly linked list. As a result any entry in table can be removed and placed in O(1) time. The only manipulation of the stack that occurs is the removal of an element from an arbitrary position in the stack to place on the top of the stack, all elements with lower recency values being propagated down the stack. This require simple pointer manipulation. To implement this, the data structure holding an individual Translation Table Entry (TTE) (or virtual to physical translation) is augmented with simple previous and next pointers with which to construct the LRU stack.
The actual value of
recency is not required because of LRU stack. LRU stack maintains entries with
increasing value of recency. So whenever a page entry is fetched on miss,
entries near to that in stack are prefetched in background. It should be noted
that prefected buffer is kept different from actual TLB and scanned in parallel
2.5
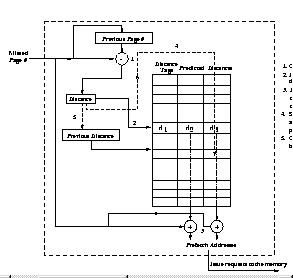
2.5 Distance prefecting(DP)
Since only repetitions in addresses can effect a prefetch for RP and MP (not first time references). They also take a while to learn pattern. Space required for this history based implementation is also quite large. DP tries to solve these problems. DP mechanism can be viewed as trying to detect many of the patterns that RP or MP can accommodate, while benefiting from the regularity strided behavior of an execution with the help of some more complex hardware. DP try to keep the track of stride (what they called distance) between successive address. The prediction table maintained by DP consist of a distance tag, and `s' predicted distance. Each entry in prediction table is indexed by distance. So if reference stream is 1, 2, 4, 5, 7... then table will be
distance predicted distance
1
2
2
1
So
whenever current distance in access pattern is 1, a entry with distance 2 will
be predicted & prefected in background. This scheme works for all access
(both hit & miss), rather than only on miss like RP. In hardware
implementation of DP, the distance table is placed on chip. Also no of entries
in predicted distance `s' may be more than one. In that case, it handle
multiple entries in same way as MP. Now Whenever a entry is referred,
corresponding `s' prediction can be prefetched. In addition, we also go to the
entry of the previous entry, and add the current distance into one of its slots
(whichever is free). If all the slots are occupied, then we evict one based on
LRU policy. Each entry has a certain number (s) of slots (maintained in LRU
order) corresponding to the next few distances that are likely to miss when the
current distance is encountered (similar to how MP keeps the next few addresses
based on the current address). Pages correspond ing to the distances in these
slots are prefetched when this virtual address misses. more aggressive scheme
can end up evicting entries before they are used.
3. CONCLUSIONS
Reference behavior can also be viewed as one of these following broadly categories:
(a) showing regular/
strided accesses to several data items that are touched only once;
(b) showing regular/ strided accesses to
several data items that are touched several times;
(c) showing regular/ strided accesses to
several data items, but the stride itself can change
over time for the same data item;
(d) not having constant strided accesses
but repeating the same irregularity from one access to
another for the same data item over
time;
(e) not having any regularity either in
strides and not obeying previous history either.
Usually stride based schemes are a better alternative than history based schemes for (a) (there is no history established here), while both categories can do well for (b). Some of the more intelligent/adaptive stride based schemes such as ASP can track (c) also fairly well, but the history based schemes are not as good for such behavior. On the other hand, history based schemes can do a much better job than stride based schemes for (d). In (e), it is very difficult for any prefecting scheme to be able to do a good job.
It should also noted that, history based scheme requires more hardware than stride based scheme. RP require more space in main memory and it also increase page table size as each entry contain pointers. All other scheme maintain table on chip. So RP may increase memory traffic. But require smallest space on chip, giving more space to prefected buffer. While RP, MP, SP work after a miss has occurred, DP and ASP work in parallel for each access. So RP, MP may require some learning.
In all these scheme, prefetched buffer is maintained along with main TLB and both are scanned parallel. MP, DP and ASP predictions depend largely on the size of the prediction table. But RP & SP do not maintain any spatial table. Simulation studies in [2] suggest that MP with 1024 entries gives nearly close result ot that of RP, while DP with 1024/512 entries was better in most of application. Following table from [2] gives average of prediction accuracy.
Arith. Average Weighted average
DP
0.43
0.82
RP
0.29
0.86
MP
0.28
0.76
ASP
0.11
0.04
4. REFERENCES
1. Ashley Saulsbury,
Fredrik Dahlgren,Per Stenström "Recency-based TLB Preloading"
2. Gokul B. Kandiraju, Anand Sivasubramaniam"Going the Distance for TLB
Prefetching:An Application-driven Study"