- Introduction
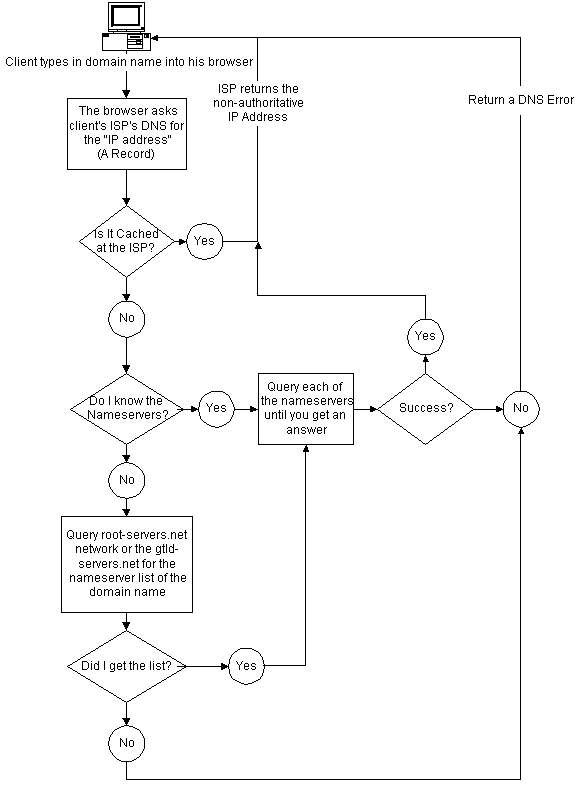
Client enters a domain name (www.domainname.com) into his browser The browser contacts the Client's ISP for the IP address of the domain name. The ISP first tries to answer by itself using "cached" data.If the answer is found it is returned. Since the ISP isn't in charge of the DNS, and is just acting as a "dns relay",the answer is marked non-authoritative".If the answer isn't found, then the ISP DNS contacts the nameservers for the domain directly for the answer.If the nameservers are not known, the ISP's looks for the information at the 'root servers', or 'registry servers'. For com/net/org, these start with a.gtld-servers.net.Figure below illustrates the following
- Name Lookup
DNS organizes hostnames in a domain hierarchy. A domain is a collection of sites that are related in some sense-because they form a proper network . For instance, universities are commonly grouped in the edu domain, with each university or college using a separate subdomain, below which their hosts are subsumed.This is a list of top level domain names:
edu - educational institutions
com - commercial organizations
org - Non commercial organizations
net - gateways & administrative hosts
mil - mil institutions
gov - US govt institutions
uucp- Officially, all site names formerly used as UUCP names without domains. In fact, DNS is a giant distributed database. It is implemented by so-called name servers that supply information on a given domain or set of domains.For each zone there are at least two, or at most a few, name servers that hold all authoritative information on hosts in that zone. To obtain the IP address of a machine in a zone, we have to contact the name server for the zone,which will then return the desired data. When your application wants to look up information on some machine,it contacts a local name server, which conducts a so-called iterative query for it. It starts off by sending a query to a name server for the root domain, asking for the address of the machine. The root name server recognizes that this name does not belong to its zone of authority, but rather to one below some other domain. Thus, it tells you to contact the corresponding domain name server for more information and encloses a list of all name servers along with their addresses.Your local name server will then go on and query one of those. In a similar manner it will iteratively query the name servers in the zone to get the IP address of the machine.
- DNS Servers
Name servers that hold all information on hosts within a zone are called authoritative for this zone, and sometimes are referred to as master name servers. Any query for a host within this zone will end up at one of these master name servers. Master servers must be fairly well synchronized. Thus, the zone's network administrator must make one the primary server, which loads its zone information from data files, and make the others secondary servers, which transfer the zone data from the primary server at regular intervals. Having several name servers distributes workload; it also provides backup. When one name server machine fails in a benign way, like crashing or losing its network connection, all queries will fall back to the other servers.You can also run a name server that is not authoritative for any domain. This is useful, as the name server will still be able to conduct DNS queries for the applications running on the local network and cache the information. Hence it is called a caching-only server.
- Database
We have seen that DNS not only deals with IP addresses of hosts, but also exchanges information on name servers. DNS databases may have, in fact, many different types of entries. A single pieceof information from the DNS database is called a resource record (RR). Each record has a type associated with it describing the sort of data it represents, and a class specifying the type of network it applies to. The prototypical resource record type is the A record, which associates a fully qualified domain name with an IP address.A host may be known by more than one name.For example you might have a server that provides both FTP and World Wide Web servers, which you give two names: ftp.machine.org and www.machine.org. However, one of these names must be identified as the official or canonical hostname, while the others are simply aliases referring to the official hostname. The difference is that the canonical hostname is the one with an associated A record, while the others only have a record of type CNAME that points to the canonical hostname.Apart from the A and CNAME records, you can see a special record at the top of the file, stretching several lines. This is the SOA resource record signaling the Start of Authority, which holds general information on the zone the server is authoritative for. The special name (@) used in the SOA record refers to the domain name by itself.
- Reverse Lookup
Finding the IP address belonging to a host is certainly the most common use for the Domain Name System, but sometimes you'll want to find the canonical hostname corresponding to an address. Finding this hostname is called reverse mapping, and is used by several network services to verify a client's identity. When using a single hosts file, reverse lookups simply involve searching the file for a host that owns the IP address in question. With DNS, an exhaustive search of the namespace is out of the question. Instead, a special domain, is created that contains the IP addresses of all hosts in a reversed dotted quad notation.
reference : http://www.faqs.org/docs/linux_network/x-087-2-resolv.howdnsworks.html
A normal web transaction takes place between a web browser and a web server. The browser, running on a local machine, contacts the web server running at a different location on the Internet and requests a particular document or other piece of data (based on the URL). Many of websites provide limited access to their websites and web servers through a technique called "domain restriction", in this case, the web server checks to see from which domain the request originated, i.e. on what part of the Internet the requesting browser is running. For the website provider, this is the most efficient way to enforce licensing restrictions over the Internet. Unfortunately, it means that many internet service providers will be denied access to "domain restricted" resources. A proxy server solves this problem by relaying ("proxying") requests between a web browser and a restricted domain. Once the
web browser has been told which proxy server to use, that machine servers as a "go between", forwarding transactions between
the browser and the actual websites from which documents are being requested. By proxying all requests through a proxy server located on Network, user can gain access to all resourrces that are "domain restricted". The resource provider's web server sees only the forwarded request from the proxy server, and thus allows the connection.Given beow are the steps involved in connection between the user and the proxy server. Once the web browser is configured, the browser will load a CGI script each time it is restarted. This script redefines the function that determines how to fetch the URL that is being requested. If the URL matches a pattern or a site that requires a proxy, it will connect to the proxy server rather than going directly to the site.
- Step 1:
User starts browser, connects to proxy server to get the Proxy Automatic Configuration (PAC) file.- Step 2:
Proxy server returns "proxy", which configures browser to do proxying.- Step 3:
User requests URL, URL compared against function retrieved from "proxy", connection route is determined.- Step 4a:
Route for URL returned from function is "DIRECT" (no proxy required). Browser retrieves URL directly.- Step 4b1:
Route for URL returned from function is "PROXY xxxxx" (proxy required). Browser contacts proxy server and requests page.- Step 4b2:
Proxy contacts server and requests page.- Step 4b3:
Server sees request from domain (proxy address) and returns URL to proxy.- Step 4b4:
Proxy returns URL to User.reference: http://www.bol.ucla.edu/services/proxy/curious.html
DHCP Server
- DHCP Protocol DHCP (Dynamic Host Configuration Protocol) is a protocol that lets network administrator manage centrally and automate the assignment of IP (Internet Protocol) configurations on a computer network. When using the Internet's set of protocols (TCP/IP), for a computer system to communicate to another computer system it needs a unique IP address. Without DHCP, the IP address must be entered manually at each computer system. DHCP lets a network administrator supervise and distribute IP addresses from a central point. The purpose of DHCP is to provide the automatic (dynamic) allocation of IP client configurations for a specific time period (called a lease period) and to eliminate the work necessary to administer a large IP network.DHCP was created by the Dynamic Host Configuration Working Group of the Internet Engineering Task Force (IETF).
- Working of DHCP When a client needs to start up TCP/IP operations, it broadcasts a request for address information. The DHCP server receives the request, assigns a new address for a specific time period (called a lease period) and sends it to the client together with the other required configuration information. This information is acknowledged by the client, and used to set up its configuration. The DHCP server will not reallocate the address during the lease period and will attempt to return the same address every time the client requests an address. The client may extend its lease with subsequent requests, and may send a message to the server before the lease expires telling it that it no longer needs the address so it can be released and assigned to another client on the network.
reference: http://www.vicomsoft.com/knowledge/reference/dhcp1.html#1
Experiment
To view the traffic between the internet browser and the proxy server I created a dummy proxy, which is a interface between the actual proxy server and the browser. Following are the steps involved
- Step1.
Create a simple network server application that listens on a particular port .- Step2.
Change the proxy address in the browser to 127.0.0.1 and the port to the above port- Step3.
The dummy server accepts connection from the browser and also the URL to be rertieved- Step4.
Create another socket which connects to the actual proxy server- Step5.
The dummy server sends the data recieved from the browser to the proxy server and waits for response- Step6.
On reception of the requested page,it sends it back to the browser.
The program was written in perl is given below.
use Socket;
socket(server,PF_INET,SOCK_STREAM,getprotobyname('tcp'));
bind(server,sockaddr_in(8001,inet_aton("127.0.0.1")));
listen(server,5);
accept(client,server);
while(1){
recv(client,$recvbuff,2000,0);
socket(proxy,PF_INET,SOCK_STREAM,getprotobyname('tcp')) or die "$!";
connect(proxy,pack('S n a4 x8',2,8080,inet_aton("144.16.67.8"))) || die "could not:$!";
send(proxy,$recvbuff,0);
recv(proxy,$recvbuff,20000,0);
print "Sending to browser....\n";
send(client,$recvbuff,0);
}
close(proxy);
close(server);
Note: This is test program, it services only one request from the browser.