Amaya is a Web editor, i.e. a tool used to create and update documents
directly on the Web. Browsing features are seamlessly
integrated
with the editing and remote access features in a uniform environment.
Amaya started as an HTML + CSS style sheets editor. Since that time it was extended to support XML and an increasing number of XML applications such as the XHTML family, MathML, and SVG. It allows all those vocabularies to be edited simultaneously in compound documents.
The current release, Amaya 8.1b, supports HTML 4.01, XHTML 1.0, XHTML
Basic, XHTML 1.1, HTTP 1.1, MathML 2.0, many
CSS 2 features,
and includes SVG support (transformation, transparency, and SMIL animation
on OpenGL platforms). You can
display and
partially edit XML documents. It's an internationalized application.
Annotea is a LEAD (Live Early Adoption and Demonstration) project enhancing
the W3C collaboration environment with shared
annotations.
By annotations we mean comments, notes, explanations, or other types of
external remarks that can be attached to any
Web document
or a selected part of the document without actually needing to touch the
document. When the user gets thedocument he or she can also load the
annotations attached to it from a selected annotation server or several
servers and see what his peer group thinks.
The first client implementation of Annotea is W3C's Amaya editor/browser.
Composite Capability/Preference
Profiles (CC/PP)
[ still to understand all the terminology]
A CC/PP profile is a description of device capabilities and user preferences that can be used to guide the adaptation of content presented to that device. The Resource Description Framework (RDF) is used to create profiles that describe user agent and proxy capabilities and preferences. The structure of a profile is discussed. Topics include:
CC/PP vocabulary is identifiers (URIs) used to refer to specific capabilities and preferences, and covers:
The status of the document is workinggroup notes. This document celebrates the vision of a device independent Web. It describes device independence principles that can lead towards the achievement of greater device independence for web content and applications.
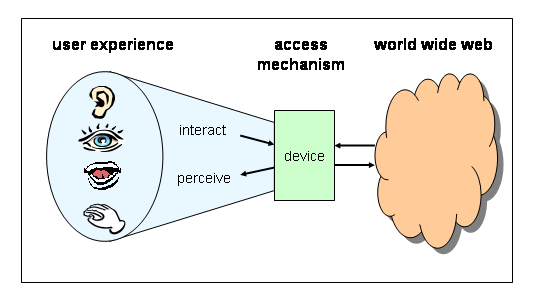
The document aims to suggest that web content and applications can be authored, generated or adapted for a better user experience when delivered via many different web-connectable access mechanisms. The general phrase "device independence" is used for this, although the access mechanisms may include a diversity of devices, user agents, channels, modalities, formats etc. The aim is to allow the Web to be accessible by anyone, anywhere, anytime, anyhow.
The focus of the is on making the Web accessible , in particular by supporting
many access mechanisms (including mobile and personal devices, that can
provide access anytime) and many modes of use (including visual and auditory
ones, that can provide access anyhow).
The main concepts for the user are as follows.
Eg: Existing devices that are commonly used to access the Web include PCs, PDAs, web-enabled phones, and interactive TVs.
The access mechanism is an intermediary between the Web and the user. On
one side it communicates with the Web using protocols and markup conventions,
on the other it supports perception by, and interaction with, the user.
The Document Object Model
is a platform- language-neutral interface that will allow programs
and scripts to dynamically access and update the content, structure and
style of documents. The document can be further processed and the results
of that processing can be incorporated back into the presented page.
"Dynamic HTML" is a term used by some vendors to describe the combination
of HTML, style sheets and scripts that allows documents to be
animated. The W3C DOM WG is working hard to make sure interoperable
and scripting-language neutral solutions are agreed upon.
HTML is the lingua franca for publishing hypertext on
the World Wide Web. It is a non-proprietary format based upon SGML, and
can be created and processed by a wide range of tools, from simple plain
text editors - you type it in from scratch- to sophisticated WYSIWYG authoring
tools. HTML uses tags such as <h1> and </h1> to structure text
into headings, paragraphs, lists, hypertext links etc.
Interested in a 10 min tutorial on html? go to
http://www.w3.org/MarkUp/Guide/
Interested in adding style to your pages ? go to http://www.w3.org/MarkUp/Guide/Style.html
The Extensible HyperText Markup Language (XHTML) is
a family of current and future document types and modules that reproduce,
subset, and extend HTML, reformulated in XML. XHTML Family document types
are all XML-based, and ultimately are designed to work in conjunction with
XML-based user agents. XHTML is the successor of HTML, and a series of
specifications has been developed for XHTML.
Three flavours of XHTML:
XHTML 1.0 Strict - Use this
when you want really clean structural mark-up, free of any markup
associated with layout. Use this together with W3C's Cascading Style Sheet
language (CSS) to get the font, color, and layout effects you want.
XHTML 1.0 Transitional - Many
people writing Web pages for the general public to access might
want to use this flavor of XHTML
1.0. The idea is to take advantage of XHTML features including style
sheets but nonetheless to make small adjustments to your markup for the
benefit of those viewing your pages with older browsers which can't understand
style sheets. These include using the body element with bgcolor, text and
link attributes.
XHTML 1.0 Frameset - Use this
when you want to use Frames to partition the browser window into two or
more frames.
XFrames is an XML application for composing documents together, replacing HTML Frames. XFrames is not a part of XHTML per se, that allows similar functionality to HTML Frames, with fewer usability problems, principally by making the content of the frameset visible in its URI.
InkML is an XML data format for representing digital ink data that is input with an electronic pen or stylus as part of a multimodal system. The markup provides a format for:
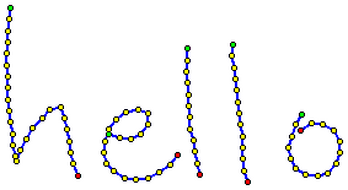
MathMLis a W3C Recommendation was released on 21 Feb 2001. A product of the W3C Math working group, MathML is a low-level specification for describing mathematics as a basis for machine to machine communication. It provides a much needed foundation for the inclusion of mathematical expressions in Web pages .
I tested Mozilla for its support for MathML. it desplayed various
mathematical equations and expressions correctly. It also gave me a warning
that
I need to install special fonts such as Math1, Math2 ,Math4 etc from
their site to view all mathematical notations correctly.
The PICS specification enables labels (metadata)
to be associated with Internet content. It was originally designed to help
parents and teachers control what children access on the Internet, but
it also facilitates other uses for labels, including code signing and privacy.
The PICS platform is one on which other rating services and filtering software
have been built.
PICS is a cross-industry working group whose
goal is to facilitate the development of technologies to give users of
interactive media, such as the Internet, control over the kinds of material
to which they and their children have access. PICS members believe that
individuals, groups and businesses should have easy access to the widest
possible range of content selection products, and a diversity of voluntary
rating systems.
PNG is an extensible file format for the lossless, portable, well-compressed storage of raster images. PNG provides a patent-free replacement for GIF and can also replace many common uses of TIFF. Indexed-color, grayscale, and truecolor images are supported, plus an optional alpha channel for transparency. Sample depths range from 1 to 16 bits per component (up to 48bit images for RGB, or 64bit for RGBA).
Mozilla
was tested for its support for PNG . It was found that it readily supports
the standard.
With existing formats, there are substantial cross-platform differences with image viewing. The images will be displayed, sure, but what people see will be very different. The problem is that the browser has no idea where the image was created or how it was originally displayed, so it cannot compensate for these differences. What is needed is for the authoring tools to include this information, which is readilly available to them. But existing image formats have no way of storing this information.
PNG stores the gamma value used by the source platform which created the image, in a standard place in the file which browsers, image viewers and authoring tools know how to read and adjust for. So the gross lightness and contrast differences are compensated for automatically, without the image designer or the reader having to make any adjustments themselves.
The Platform for Privacy Preferences Project (P3P), developed by the World Wide Web Consortium, is emerging as an industry standard providing a simple, automated way for users to gain more control over the use of personal information on Web sites they visit. At its most basic level, P3P is a standardized set of multiple-choice questions, covering all the major aspects of a Web site's privacy policies. Taken together, they present a clear snapshot of how a site handles personal information about its users. P3P-enabled Web sites make this information available in a standard, machine-readable format. P3P enabled browsers can "read" this snapshot automatically and compare it to the consumer's own set of privacy preferences. P3P enhances user control by putting privacy policies where users can find them, in a form users can understand, and, most importantly, enables users to act on what they see.
At its most basic level, P3P is a machine-readable vocabulary
and syntax for expressing a Web site´s data management practices.
Taken together, a site´s P3P policies present a snapshot summary of
how the site collects, handles and uses personal information about its visitors.
P3P-enabled Web browsers and other P3P applications will read
and
understand
Implementing P3P go to site :http://p3ptoolbox.org/guide/
The Resource Description Framework (RDF) is a general-purpose
language for representing information in the Web. This specification describes
how to use RDF to describe RDF vocabularies. This specification defines
a vocabulary for this purpose and defines other built-in RDF vocabulary
initially specified in the RDF Model and Syntax Specification. It is
particularly intended for representing metadata about Web resources,
such as the title, author, and modification date of a Web page, copyright
and licensing information about a Web document, or the availability
schedule for some shared resource. However, by generalizing the concept
of a "Web resource", RDF can also be used to represent information
about things that can be identified on the Web, even when
they cannot be directly retrieved on the Web. Examples include
information about items available from on-line shopping facilities
(e.g., information about specifications, prices, and availability),
or the description of a Web user's preferences for information
delivery.
RDF is intended for situations in which this information needs to be processed by applications, rather than being only displayed to people. RDF provides a common framework for expressing this information so it can be exchanged between applications without loss of meaning. Since it is a common framework, application designers can leverage the availability of common RDF parsers and processing tools. The ability to exchange information between different applications means that the information may be made available to applications other than those for which it was originally created.RDF is based on the idea of identifying things using Web identifiers (called Uniform Resource Identifiers, or URIs), and describing resources in terms of simple properties and property values. This enables RDF to represent simple statements about resources as a graph of nodes and arcs representing the resources, and their properties and values.
There is a person identified by http://www.w3.org/People/EM/contact#me,
whose name is Eric Miller, whose email address is em@w3.org, and
whose title is Dr." could be represented as the RDF graphshown in
figure 
Extensible Markup Language (XML) is a simple, very
flexible text format derived from SGML . Originally designed to meet
the challenges of large-scale electronic publishing, XML is also playing
an increasingly important role in the exchange of a wide variety of
data on the Web and elsewhere.
The XML Linking Language Xlink defines Extensible Markup Language (XML) 1.0 constructs to describe links between resources. One of the stated requirements on XLink is to support HTML linking constructs in a generic way. The HTML BASE element is one such construct which the XLink Working Group has considered. BASE allows authors to explicitly specify a document's base URI for the purpose of resolving relative URIs in links to external images, applets, form-processing programs, style sheets, and so on.
Online tutorial :http://www.w3schools.com/xml/default.asp
XML was designed to describe data and focus on what data is.
HTML was designed to display data and focus on how data
looks.
XML was designed to carry data.
XML is not a replacement for HTML.
XML and HTML were designed with different goals:
XML was designed to describe data and to focus on what data is.
HTML was designed to display data and to focus on how data looks.
HTML is about displaying information, while XML is about describing information.
XML was not designed to DO anything.
Maybe it is a little hard to understand, but XML does not DO anything.
XML is created to structure, store and to send information.
XPath is the result of an effort to provide a common syntax and semantics for functionality shared between XSL Transformations[XSLT] and XPointer . The primary purpose of XPath is to address parts of an XML document. In support of this primary purpose, it also provides basic facilities for manipulation of strings, numbers and booleans. XPath uses a compact, non-XML syntax to facilitate use of XPath within URIs and XML attribute values. XPath operates on the abstract, logical structure of an XML document, rather than its surface syntax. XPath gets its name from its use of a path notation as in URLs for navigating through the hierarchical structure of an XML document.
XPath models an XML document as a tree of nodes. There are different types of nodes, including element nodes, attribute nodes and text nodes. XPath defines a way to compute a string value. for each type of node. Some types of nodes also have names. XPath fully supports XML Namespaces [XML Names]. Thus, the name of a node is modeled as a pair consisting of a local part and a possibly null namespace URI; this is called an expanded-name. The data model is described in detail in 5 Data Model.
Expression evaluation occurs with respect to a context. XSLT and XPointer specify how the context is determined for XPath expressions used in XSLT and XPointer respectively. The context consists of: